如何用 AI 精確生成 Porn Video
掌握兩步法精確控制AI影片生成:用首幀圖鎖定畫面,用分步指令控制動作。告別AI亂猜,80%的鏡頭都能輕鬆掌控。
很多新手第一次用 PornPop AI 生成影片時,都會碰到同一個問題:我明明給了圖片和提示詞,AI 做出來的效果就是不對。
你想要鏡頭緩緩推進到人物臉部,結果鏡頭亂飛;你想要女主角回頭微笑,結果動作完全不是那回事;你設想的是黑色街道、風吹髮動的電影感,結果背景風格大變樣。
這不是你的提示詞寫得差,問題出在一個更根本的地方——你對 AI 生成影片的工作方式理解有誤。
AI 不是在「執行」,而是在「猜」
AI 並不會精準複現你腦中的畫面。它的工作方式更接近於:根據你給出的有限資訊,猜測並補全一個「合理」的影片。
問題在於:你腦中的畫面是完整的,但你傳遞給 AI 的資訊往往遠遠不夠。
比如你寫了一句 「一個女孩在海邊回頭,電影感」,你腦中其實已經補齊了大量預設細節——女孩的年齡、穿著、回頭的速度、鏡頭是手持還是固定、畫面是暖色還是冷色。但這些資訊你並沒有告訴 AI,於是 AI 只能自己亂補,結果自然和你想的不一樣。

你腦中有 8 個細節,AI 實際只收到了 2 個——剩下的全靠猜。
解決方案:兩步法
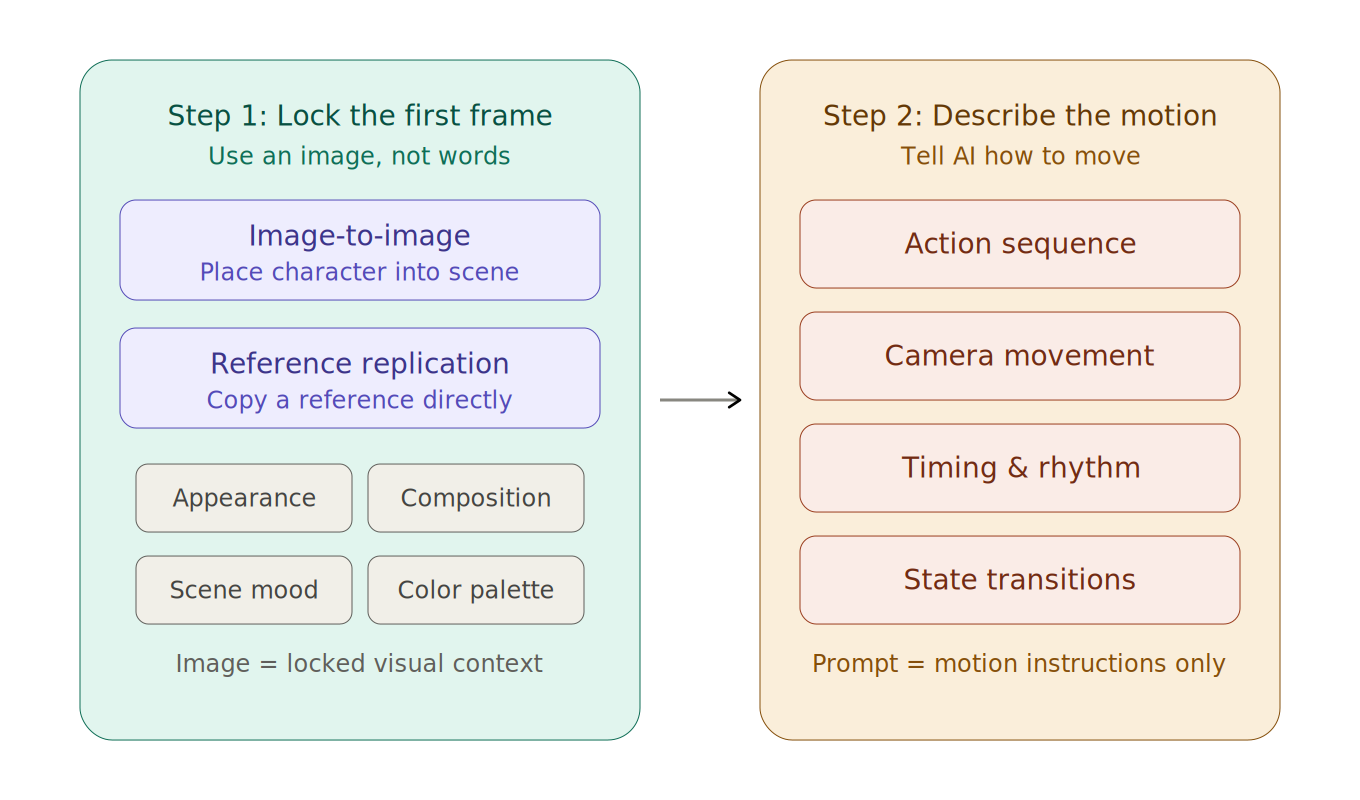
與其死磕提示詞技巧,不如用一個更高效的方法來掌控影片生成——把過程拆成兩步:先鎖畫面,再加動作。
第一步:用圖片鎖定第一幀
把自己想像成導演。開拍前,你會先讓演員站進場景、擺好位置,然後再喊「Action」。首幀圖就是你喊 Action 前的那一瞬間。
用一張精確的圖片代替語言描述,能一次性鎖定人物外觀、場景氛圍、構圖和色彩——這些都不再需要 AI 去猜。
在 PornPop 中,有兩種方式快速生成首幀圖:
第二步:只描述「怎麼動」
首幀圖搞定後,你的提示詞只需要專注一件事:告訴 AI 畫面該如何運動。
這裡有兩個關鍵原則:
原則一:動作要可分解。 不要寫「她很自然地走動」這樣籠統的描述,而要把動作拆成一個個清晰的步驟。

左邊的模糊描述,AI 只能猜;右邊的分步指令,AI 才能精確跟隨。
原則二:鏡頭語言單獨寫。 影片效果很大程度取決於鏡頭,而不只是畫面內容。鏡頭資訊最好單獨給出,例如:固定機位、緩慢推進、中景到近景、輕微手持感、跟隨人物移動、環繞旋轉。
總結
| 常規做法 | 兩步法 | |
|---|---|---|
| 畫面資訊 | 全靠文字描述 | 用首幀圖一次鎖定 |
| 動作描述 | 籠統一句話 | 逐步分解 + 鏡頭單獨寫 |
| AI 的猜測空間 | 非常大 | 大幅縮小 |
| 可控性 | 低 | 高 |
掌握兩步法,80% 的鏡頭都可以輕鬆掌控。
關於提示詞的進階技巧,我們後續再聊。祝你玩得開心!