如何用 AI 精确生成 Porn Video
掌握两步法精确控制AI视频生成:用首帧图锁定画面,用分步指令控制动作。告别AI乱猜,80%的镜头都能轻松掌控。
很多新手第一次用 PornPop AI 生成视频时,都会碰到同一个问题:我明明给了图片和提示词,AI 做出来的效果就是不对。
你想要镜头缓缓推进到人物脸部,结果镜头乱飞;你想要女主角回头回微笑,结果动作完全不是那回事;你设想的是黑色街道、风吹发动的电影感,结果背景风格大变样。
这不是你的提示词写得差,问题出在一个更根本的地方——你对 AI 生成视频的工作方式理解有误。
AI 不是在"执行",而是在"猜"
AI 并不会精准复现你脑中的画面。它的工作方式更接近于:根据你给出的有限信息,猜测并补全一个"合理"的视频。
问题在于:你脑中的画面是完整的,但你传递给 AI 的信息往往远远不够。
比如你写了一句 "一个女孩在海边回头,电影感",你脑中其实已经补齐了大量默认细节——女孩的年龄、穿着、回头的速度、镜头是手持还是固定、画面是暖色还是冷色。但这些信息你并没有告诉 AI,于是 AI 只能自己瞎补,结果自然和你想的不一样。

你脑中有 8 个细节,AI 实际只收到了 2 个——剩下的全靠猜。
解决方案:两步法
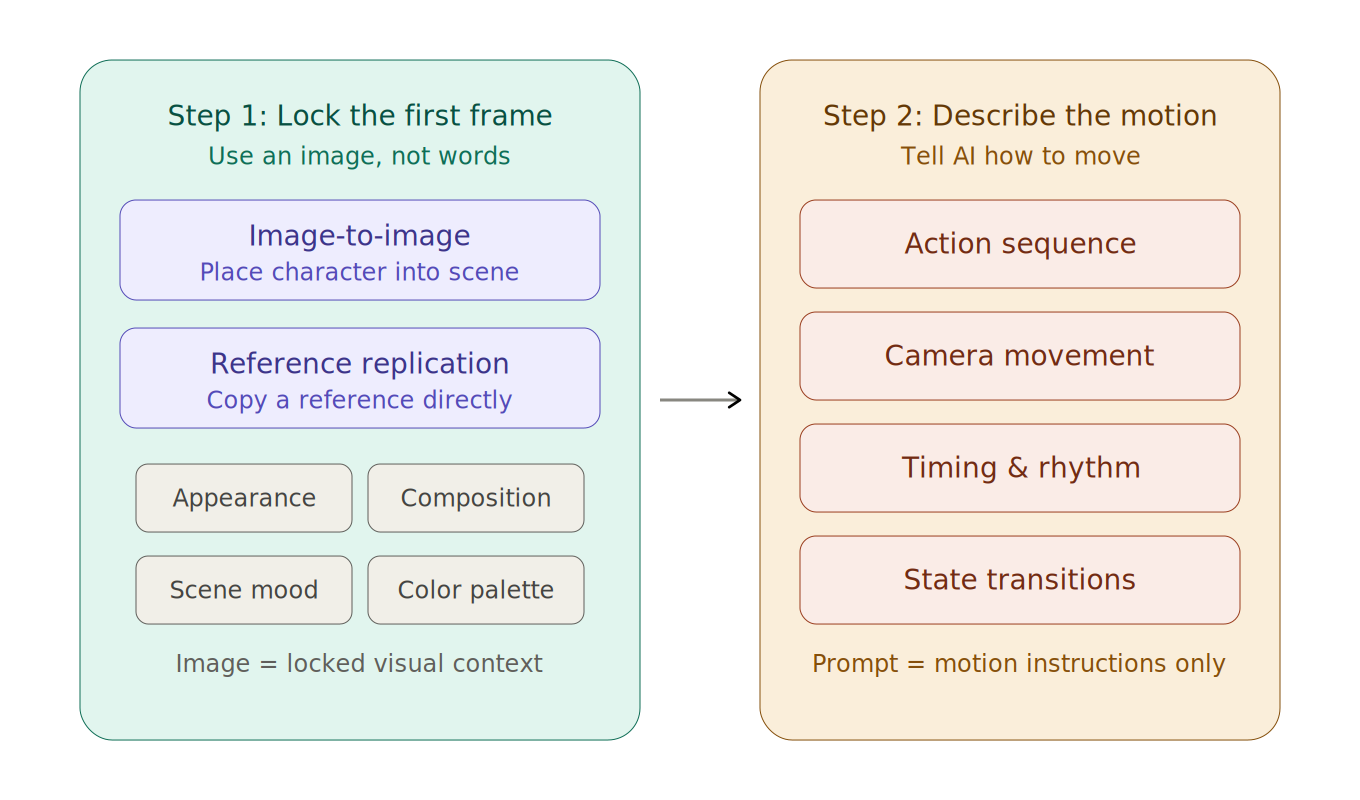
与其死磕提示词技巧,不如用一个更高效的方法来掌控视频生成——把过程拆成两步:先锁画面,再加动作。
第一步:用图片锁定第一帧
把自己想象成导演。开拍前,你会先让演员站进场景、摆好位置,然后再喊"Action"。首帧图就是你喊 Action 前的那一瞬间。
用一张精确的图片代替语言描述,能一次性锁定人物外观、场景氛围、构图和色彩——这些都不再需要 AI 去猜。
在 PornPop 中,有两种方式快速生成首帧图:
第二步:只描述"怎么动"
首帧图搞定后,你的提示词只需要专注一件事:告诉 AI 画面该如何运动。
这里有两个关键原则:
原则一:动作要可分解。 不要写"她很自然地走动"这样笼统的描述,而要把动作拆成一个个清晰的步骤。

左边的模糊描述,AI 只能猜;右边的分步指令,AI 才能精确跟随。
原则二:镜头语言单写。 视频效果很大程度取决于镜头,而不只是画面内容。镜头信息最好单独给出,例如:固定机位、缓慢推进、中景到近景、轻微手持感、跟随人物移动、环绕旋转。
总结
| 常规做法 | 两步法 | |
|---|---|---|
| 画面信息 | 全靠文字描述 | 用首帧图一次锁定 |
| 动作描述 | 笼统一句话 | 逐步分解 + 镜头单独写 |
| AI 的猜测空间 | 非常大 | 大幅缩小 |
| 可控性 | 低 | 高 |
掌握两步法,80% 的镜头都可以轻松掌控。
关于提示词的进阶技巧,我们后续再聊。祝你玩得开心!