AIでPorn Videoを正確に生成する方法
2ステップ法でAI動画生成を正確にコントロール:最初のフレーム画像で画面を固定し、段階的な指示で動きを制御。AIの推測に頼らず、80%のショットを簡単にコントロールできます。
多くの初心者がPornPop AIで初めて動画を生成する時、同じ問題にぶつかります:画像もプロンプトもちゃんと入力したのに、AIが作った結果が思い通りにならない。
カメラがゆっくり人物の顔に寄っていくはずが、カメラがめちゃくちゃに動く。女性が振り向いて微笑むはずが、まったく違う動きになる。暗い街並みに風で髪がなびく映画的なシーンを想像していたのに、背景のスタイルがガラリと変わってしまう。
これはプロンプトの書き方が悪いのではありません。もっと根本的なところに問題があります——AI動画生成の仕組みに対する理解が間違っているのです。
AIは「実行」しているのではなく、「推測」している
AIはあなたの頭の中の映像を正確に再現するわけではありません。AIの動作方式はむしろこうです:あなたが提供した限られた情報をもとに、「もっともらしい」動画を推測して補完する。
問題は、あなたの頭の中の映像は完全なのに、AIに伝わる情報が圧倒的に不足していることです。
例えば 「海辺で女の子が振り向く、映画的な雰囲気」 と書いたとします。あなたの頭の中ではすでに多くのデフォルトの詳細が補完されています——女の子の年齢、服装、振り向く速度、カメラは手持ちか固定か、画面は暖色系か寒色系か。しかしこれらの情報はAIに伝えていないので、AIは自分で勝手に補完するしかなく、結果が想像と違うのは当然です。

あなたの頭の中には8つのディテールがあるのに、AIが実際に受け取ったのは2つだけ——残りはすべて推測です。
解決策:2ステップ法
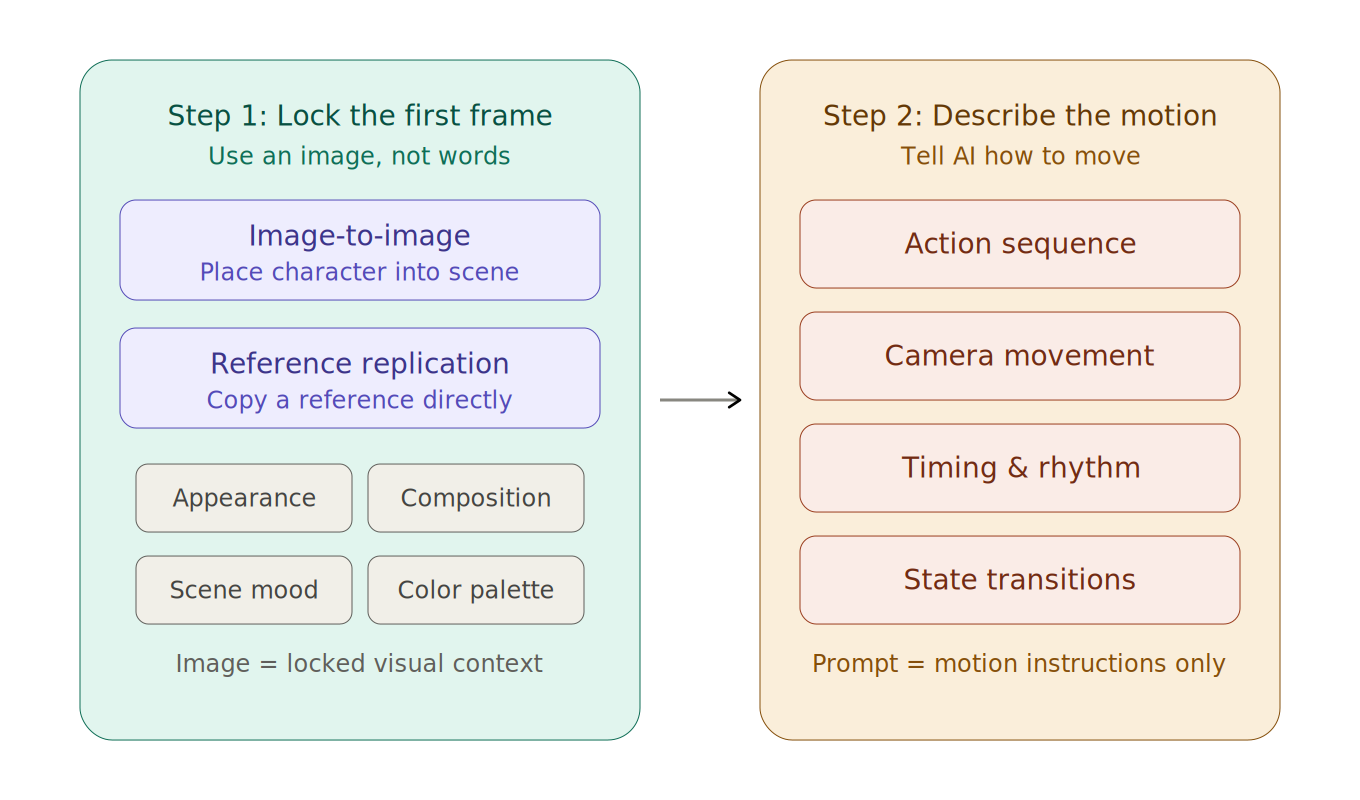
プロンプトのテクニックに固執するより、もっと効率的な方法で動画生成をコントロールしましょう——プロセスを2つのステップに分ける:まず画面を固定し、次に動きを加える。
第1ステップ:画像で最初のフレームを固定する
自分を映画監督だと想像してください。撮影前に、まず俳優をシーンに立たせて位置を決め、それから「アクション!」と声をかけます。最初のフレーム画像とは、「アクション!」と叫ぶ直前の瞬間です。
正確な画像を言葉の説明の代わりに使うことで、人物の外見、シーンの雰囲気、構図、色彩を一度に固定でき、AIに推測させる必要がなくなります。
PornPopでは、最初のフレーム画像を素早く生成する2つの方法があります:
第2ステップ:「どう動くか」だけを記述する
最初のフレーム画像が決まったら、プロンプトは一つのことに集中するだけです:画面がどう動くかをAIに伝える。
ここで2つの重要な原則があります:
原則1:動きは分解可能にする。 「彼女が自然に歩く」のような曖昧な記述ではなく、動きを一つずつ明確なステップに分解します。

左側の曖昧な記述では、AIは推測するしかない。右側のステップ別指示なら、AIは正確に従えます。
原則2:カメラワークは別に記述する。 動画の出来栄えはカメラワークに大きく左右されますが、画面内容だけではありません。カメラの情報は別途指定するのがベストです。例えば:固定カメラ、ゆっくりズームイン、ミディアムショットからクローズアップ、軽い手持ち感、人物を追従、回転移動など。
まとめ
| 通常のやり方 | 2ステップ法 | |
|---|---|---|
| 画面情報 | すべてテキストで記述 | 最初のフレーム画像で一括固定 |
| 動きの記述 | 曖昧な一文 | ステップ別分解 + カメラワーク別記述 |
| AIの推測余地 | 非常に大きい | 大幅に縮小 |
| コントロール性 | 低い | 高い |
2ステップ法をマスターすれば、80%のショットを簡単にコントロールできます。
プロンプトの上級テクニックについては、また別の機会に。楽しんでください!